




مقدمه
در مبحث مربوط به آواشناسی به بیان خصوصیات صداها از نظر نحوه و مکان تولید آنها پرداختیم. همانطور که میدانید انسانها دارای خصوصیات فیزیکی خاصی هستند که آنها را از یکدیگر متمایز میسازد. این تفاوت در خصوصیات فیزیکی تنها به اندامهایی نظیر دست و بازو مربوط نبوده و شامل کوچکترین اعضای بدن مانند تارهای صوتی هم میشود. تارهای صوتی درون حنجرهی افراد از نظر اندازه و شکل با یکدیگر متفاوت بوده و همین تفاوت باعث میشود افراد لغات مشابه را به شکلی متفاوت از یکدیگر تلفظ کنند. بنابراین اگر دو شخص انگلیسی زبان لغتی مانند water را به زبان بیاورند، همیشه در نحوهی تلفظ آنها (از نظر آوایی) تفاوتهایی وجود دارد. یعنی خصوصیات آوایی لغت water آنگونه که توسط فرد اول تولید شده با خصویات آوایی water آنگونه که توسط فرد دوم تولید شده هیچگاه کاملاً یکسان نیست. حتی مطالعات نشان دادهاند که خصویات آوایی یک لغت هم که چند بار توسط یک شخص تولید میشوند با یکدیگر متفاوت هستند. این بدان معناست که اگر شما 5 بار پشت سر هم لغت water را به زبان بیاورد همچنان بین این لغات از نظر آوایی تفاوتهایی وجود دارد. هدف از ذکر این موضوع بیان این مسأله است که با وجود چنین تفاوتهایی مغز ما چگونه قادر به تشخیص این لغات است و یک لغت با هزاران تنوع آوایی را از لغات دیگر متمایز میسازد؟
واج شناسی یا phonology چیست؟
پاسخ سوال فوق را باید در علم واج شناسی یا همان phonology جستجوکرد. به بیان ساده واج شناسی را میتوان شاخهای از زبانشناسی دانست که به مطالعه و توصیف سیستمهای آوایی در زبان میپردازد. هر شخص بدون آنکه خود آگاه باشد سیستم آوایی زبان مادری خود را میداند و درستی یا نادرستی کلمات را بر پایهی آن میسنجد. اگر به شما بگویند که یک شخص انگلیسی زبان هنگام فارسی صحبت کردن دو لغت ” شراز” و شژچ” را به زبان آورده، و از شما بخواهند که حدس بزنید آن شخص این کلمات را بجای چه کلماتی بکار برده، به احتمال زیاد بگویید که منظور او از “شراز”، (فراز، تراز، گُراز، هراز، یا حتی شیراز) بوده. در مورد “شژچ” اما به احتمال زیاد نتوانید هیچ لغتی را پیشنهاد دهید. دلیل این امر آن است که صداهای /ه/، /ت/،/گ/،/ش/ و /ف/ خصوصیات آوایی مشترکی دارند و در سیستم زبانی مغز ما فارسی زبانان همهی آنها اجازهی همنشینی با صدای /ر/ را دارند. به همین خاطر است که ما حدس میزنیم ممکن است منظور آن فرد خارجی از “شراز” یکی از لغات فوق بوده باشد. به همین ترتیب اشتراکات آوایی دو صدای / ر/ و / ز/ به ما این اجازه را میدهد که واژهی “شرار” را هم به جای “شراز” پیشنهاد دهیم. اما چرا نمیتوانیم برای لغت “شژچ” هیچ واژهایی پیشنهاد کنیم؟ اگر به یاد داشته باشید صداهای /ش/، /ژ/، و /چ/ همه از خانوادهی صداهای palatal هستند. در سیستم آوایی زبان فارسی ( و بسیاری از زبانهای دیگر ) سه صدای palatal اجازهی همنشینی با یکدیگر را ندارند. در واقع در قسمت آوایی مغز ما هیچ لغت دیگری وجود ندارد که در آن سه صدای palatal در کنار هم قرار گرفته باشند. به همین دلیل مغز ما نمیتواند واژهایی برای “شژچ” پیشنهاد بدهد.
اهمیت علم واج شناسی
هنگامیکه میگوییم صدای /s/ درکلماتی مانند student, ask, و class صدایی ثابت و یکسان است، منظورمان این است که این صدا در علم آواشناسی به یک شکل ثابت نشان داده میشود. اما هنگام صحبت کردن، صدای /s/ موجود در این لغات به هیچ وجه یکسان نبوده و تفاوتهای قابل توجهی با یکدیگر دارند. اما اهمیت این تفاوت به اندازهی اهمیت تفاوت بین /s/ و /t/ در کلمات tea و sea نیست. دلیل این امر آن است که در مورد اول هر یک از متغییرهای /s/ را که بهکار ببریم، لغات مورد نظر ما یعنی لغات (student, ask, class) همچنان معنی خود را حفظ میکنند. اما در مورد دوم وقتی به جای /s/ صدای /t/ را بکار ببریم، معنای لغت مورد نظر ما کاملاً عوض میشود. بنابراین میتوان گفت که phonology به مطالعهی الگوهای آوایی مربوط میشود که به درک صحیح ما از آنچه که میشنویم میانجامد. تنها به کمک phonology است که ذهن ما قادر به تشخیص تفاوت بین دو لغت sea و tea میشود.
Phones, phonemes, and allophones
برای درک بهتر phonology باید با سه مفهوم phone, phoneme, و allophone آشنا شویم و تفاوت آنها با یکدیگر را بدانیم. بیایید ابتدا از phoneme شروع کنیم.
Phone and phoneme
در منابع بسیاری phoneme به عنوان کوچکترین عضو آوایی در زبان معرفی شده که تفاوت معنایی ایجاد میکند. این تعریف شاید رایجترین تعریف از phoneme باشد. اما منظور از این تعریف چیست؟ در مثال فوق ذکر کردیم که دو لغت tea و sea با یکدیگر تفاوت معنایی دارند. چیزی که این دو کلمه را از هم متمایز میسازد همان phoneme یا واج است. اگر به برادر یا خواهر کوچکتان که هنوز خواندن و نوشتن نمیداند لغت “پدر، خانه، یا ماشین” را نشان دهید، او معنی این کلمات را متوجه نمیشود و هیچ درکی از این لغات نخواهد داشت. اما به محض اینکه این لغات را برای او بخوانید، او معنای این کلمات را درک میکند.
میدانیم که اولین مرحلهی یادگیری زبان مادری یادگیری اصوات آن زبان است. هنگامیکه برادر یا خواهر کوچک شما واژهی “پدر” را میشنود، ابتدا اصوات [پ، د، ر] را درک میکند و سپس با کنار هم قرار دادن آنها به مفهوم واژهی پدر میرسد. بنابراین میتوان نتیجه گرفت که هر شخص سالمی بدون نیاز به خواندن و نوشتن درکی صحیح از اصوات و کلمات زبان مادری خود دارد. این تصویر یا درک ذهنی از اصوات، phoneme یا همان واج است. به یاد داشته باشید که ما phone را تولید میکنیم ( یعنی آن را به زبان میاوریم طوری که دیگران آن را میشنوند) حال آنکه phoneme تصویری ذهنی از phone است که فقط در ذهن ما وجود دارد و قابل بیان یا شنیدن نیست. به محض اینکه صدا تولید میشود از مرحله phoneme بودن خارج و به یک phone تبدیل شده. در حالت کلی phone و phoneme دو تفاوت اساسی دیگر با هم دارند که آنها را با هم بررسی میکنیم.
- Phone واحد بنیادی در آواشناسی محسوب میشود حال آنکه phoneme واحدی بنیادی در واجشناسی به حساب میآید.
- Phone را همیشه در براکت [ ] نشان میدهیم حال آنکه phoneme را در اسلش / / بکار میبریم. پس [t] نشانگر یک phone و /t/ نشانگر یک phoneme است.
حال این سوال پیش میآید که در زبان انگلیسی چند phoneme وجود دارد؟ تمام صداهایی که تفاوت معنایی ایجاد میکنند یک phoneme محسوب میشوند که لیست کامل این phonemeها را میتوانید در مقالهی مربوط به آواشناسی ملاحظه بفرمایید.
Allophones
پیشوند “allo” به معنای “جزئی از یک مجموعهی مرتبط” است. بنابراین allophone به صدایی اطلاق میشود که با چند صدای دیگر ( که همگی زیرمجموعهی یک صدا هستند)، اشتراکات آوایی خاصی دارد. پیشتر اشاره کردیم که صدای [s] موجود در سه لغت (student, class, ask) یکسان نیستند. در اینجا [s] یک phone با سه متغییر است. هر یک از این متغییرها یک allophone است. یک مثال محسوس تر میتواند صدای [l] در کلمات people و clear باشد. یک انگلیسی زبان صدای [l] موجود در این لغات را به دو شکل متفاوت تلفظ میکند. صدای [l] موجود در کلمهی clear به همان شکلی که ما فارسی زبانان عادت داریم تلفظ میشود. اما صدای [l] موجود در کلمهی people با فشار(یا بهتر است بگوییم با غلظت) بیشتری تولید میشود. پس صدای [l] دو allophone دارد. یکی light/soft و دیگری dark. به همین خاطر در نشان دادن علائم فونوتیکی آنها به ترتیب از [l] و [ɫ] استفاده میشود. به همین ترتیب صدای [t] چهار allophone دارد که آنها را در تصویر زیر مشاهده میکنید.

Minimal pairs and minimal sets
برای آنکه یک واج را از واج دیگر تشخیص بدهیم کافی است بدنبال کلماتی بگردیم که در تمام صداها بجز یک صدا مشترک هستند. به عنوان مثال اگر دو لغت bit و but را با هم مقایسه کنیم متوجه میشوییم که آنها تنها در صدای میانی با هم اختلاف دارند و این اختلاف صدا اختلاف معنی هم بدنبال دارد. بنابراین میتوانیم نتیجه بگیریم که /i/ و /ʌ / دو واج مجزا هستند. علاوه بر این میتوان گفت که دو لغت bit و but یک minimal pair را تشکیل میدهند. پس minimal pair به دو لغت اطلاق میشود که تعداد صداهای برابری دارند و تنها در یک صدا اختلاف دارند. توجه داشته باشید که جای این صدا باید در هر دو لغت یکسان باشد یعنی هر دو لغت در صدای دوم یا سوم…..اختلاف داشته باشند. هر گاه چند لغت داشته باشیم که همگی تنها در یک صدا با هم اختلاف داشته باشند و مکان آن صدا در تمامی آن لغات یکسان باشد، میتوانیم آن لغات را یک minimal set بنامیم. بنابراین میتوان گفت که لغات (bit, but, bet, bat, boot) یک minimal set را تشکیل میدهند.
Phonotactics
Phonotactics یکی از زیرشاخههای phonology است که قواعد همنشینی آواها در یک زبان را بررسی میکند. در ابتدای این مقاله گفتیم که در هر زبان هر صدا ، بسته به جایگاهش در یک کلمه، اجازهی همنشینی با تعداد محدودی از دیگر صداها را دارد. زبان فارسی هیچ جایگزینی که از نظر آوایی مشابه لغت ساختگی ما یعنی “شژچ” باشد، ندارد زیرا قواعد phonotactics زبان فارسی اجازهی ساخت چنین لغتی را نمیدهند. در زبان انگلیسی نیز به همین دلیل نمیتوانید واژهاگانی مانند gfri یا zxro بیابید. پس phonotactics الگوهای آوایی مجاز در یک زبان را مشخص میکند که تمام واژگان جدیدی که وارد آن زبان میشوند باید با یکی از این الگوها تطابق داشته باشند. برای درک بهتر phonotactics و شناخت الگوهای آوایی مجاز در زبان انگلیسی لازم است با یک واحد زبانی دیگر یعنی یا syllable آشنا شویم.
Syllable
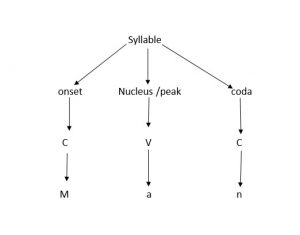
همگی ما از دوران ابتدایی بخش کردن لغات را به یاد میآوریم. وقتی که معلممان از ما میخواست لغاتی مانند ( بابا، مادر، نانوا……) و غیره را بخش کنیم. حتماً میدانید که این کلمات از دو بخش (با-با)، (ما- در)، و (نان- وا) تشکیل شدهاند. هر یک از این بخشها یک syllable هستند و وجه مشترک همهی آنها دارا بودن یک مصوت است. پس در تعریف syllable میتوان گفت که syllable یک واحد زبانی است که از یک مصوت یا شبه مصوت (vowel or vowel-like sound) و یک یا چند صامت تشکیل شده است. لغت man تنها یک syllable دارد و در مقابل طولانیترین لغت موجود در زبان انگلیسی یعنی لغت pneumonoultramicroscopicsilicovolcanoconiosis داری نوزده syllable است. اما اکثر لغات انگلیسی بین سه تا پبج syllable دارند. میدانید که حروف صامت را در انگلیسی consonant و حرف مصوت را vowel مینامیم. هنگامی که ساختار یک syllable را بررسی میکنیم، بجای consonant ها از C و بجای vowel ها از V استفاده میکنیم. پس ساختار واژهی man که تنها یک syllable دارد به این شکل نشان داده میشود (man= CVC).
اجزای syllable
یک syllable از دو قسمت اصلی تشکیل میشود. onset به قسمت اول syllable گفته میشود که دارای یک یا چند consonant است. قسمت دوم syllable هم rhyme نامیده میشود که خود از دو قسمت nucleus/peak و coda تشکیل میشود. nucleus متشکل از یک vowel است و coda هم متشکل از یک یا چند consonant پس ساختار یک syllable را میتوانیم به شکل زیر ترسیم کنیم.

بنابراین ساختار واژهی man را میتوان به شکل زیر ترسیم کرد.
برخی syllable ها مانند we, hi, و go تنها دارای onset و nucleus یا peak بوده و coda ندارند. اینگونه syllableها را open syllable مینامیم. از طرف دیگر برخی syllableها مانند on, up, و ink قسمت onset نداشته اما coda دارند. اینگونه syllableها را closed syllable مینامیم.
Consonant Clusters
همانطور که در قسمت قبل ذکر شد onset و coda میتوانند بیشتر از یک consonant را در خود جای دهند. هر گاه در یکی از این قسمتها دو یا چند consonant در کنار هم قرار میگیرند یک consonant cluster را تشکیل میدهند. ساختار واژهی print را میتوانیم به شکل (CCVCC) نشان دهیم. بنابراین دراین واژه دو consonant cluster وجود دارند که عبارتند از (pr) و (nt) . اگر consonant cluster موجود در قسمت onset تنها متشکل از دو consonant باشد، ترتیب این consonantها از دو حالت خارج نیست که این دو حالت را در اینجا مورد بررسی قرار میدهیم. در حالت اول consonant اول [s] و consonant دوم یکی از صداهای [p, t, k, f, m, n, l, w, j ] خواهد بود. لغات زیر نمونههایی از اینگونه consonant cluster ها هستند. برای درک بهتر این مطلب، در این قسمت از فرم “آوا نوشته” استفاده میکنیم. منظور از آوا نوشته نگارش کلمات یا جملات به آن شکل که بیان میشوند است، نه آنگونه که نوشته میشوند.
(Speak, Student, sphere, sky smoke, snow, slow, swim, syringe)
/ spiːk- stjuːd(ə)nt – sfɪə – skʌɪ – sməʊk – snəʊ – sləʊ – swɪm – srɪndʒ/
در چنین حالتی صدای [s] را initial consonant و صدای بعد از [s] را post-initial consonant مینامیم. در حالت دوم ممکن است یکی از پاندزه consonant زیر به عنوان initial consonant و یکی از صداهای [l, r, w, j ] به عنوان post-initial consonant تشکیل دهندهی coda باشند. این پاندزه consonant عبارتند از:
[ p, t, k, b, d, g, f, θ, s, ʃ, h, v, m, n, l ]
جدول زیر نمونههای از این حالت را نشان میدهد.

در قسمت onset بیشتر از سه consonant قرار نمیگیرند. در چنین مواردی صدای [s] به عنوان صدای اول بکار میرود که به آن pre-initial consonant میگوییم. پس از صدای [s] یکی از صداهای [p, t, k] قرار میگیرد که در این جایگاه به آنها initial consonant میگوییم. در نهایت صدای سوم یکی از صداهای [l, r, w] خواهد بود که در این جایگاه به آنها post-initial consonants میگوییم. جدول زیر این حالت را نشان میدهد.

در قسمت coda هم نهایتاٌ چهار consonant ممکن است کنار هم قرار بگیرند. حال اگر در قسمت coda تنها یک consonant قرار بگیرد آن consonant را final consonant مینامیم. در قسمت coda بجز صداهای [h, w. j ] تمامی consonant های دیگر میتوانند در جایگاه final consonant قرار بگیرند. اگر دو consonant در قسمت coda قرار بگیرند، دو حالت ممکن است پیش بیاید.
- حالت اول: یکی از صداهای [m, n, ŋ, l, s] به عنوان pre-final consonant قرار میگیرد و پس از آن یک consonant به عنوان final consonant میآید. لغات زیرکه به شکل آوا نوشته آمدهاند، نمونههای این حالت را نشان میدهند.
/ lʌmp -vɛnt – raŋk – mɛlt- dɛsk- /
- حالت دوم: در حالت دوم یک consonant به عنوان final consonant آمده و پس از آن یکی از صداهای [s, z, t, d, θ ] به عنوان post-final consonant قرار میگیرد. آوانوشتههای زیر نمونههایی از این حالت را نشان میدهند.
/ lɛts- bɛdz- takt- laɡd – eɪtθ /
اگر در قسمت coda سه consonant قرار بگیرند هم دو حالت ممکن است پیش بیایید. در حالت اول consonant اول pre-final consonant نامیده میشود، consonant دوم در جایگاه final consonant ، و consonant سوم در جایگاه post-final consonant قرار میگیرد. جدول زیر چنین حالتی را نشان میدهد.

در حالت دوم، consonant اول در جایگاه final consonant قرار میگیرد. Consonant دوم در جایگاه post-final consonant 1 و consonant سوم هم در جایگاه post-final consonant 2 قرار میگیرند. جدول زیر نشان دهندهی این حالت است.

اگر در قسمت coda چهار consonant قرار بگیرند، consonant اول pre-final consonant خواهد بود. consonant دوم به عنوان final consonant شناخته میشود. Consonant سوم در جایگاه post-final consonant 1 قرار میگیرد و consonant چهارم هم در این حالت به عنوان post-final consonant 2 شناخته میشود. جدول زیر چنین حالتی را نشان میدهد.
| Post-final 2 | Post-final 1 | final | Pre-final | cluster | Word |
| t | s | p | m | mpst | glimpsed |
| s | θ | d | n | ndθs | thousandths |
| s | θ | f | l | lfθs | twelfths |
Coarticulation effects
پس از آشنایی با اجزای syllable نوبت آن است که با تغییرات صداها در زمان صحبت کردن آشنا شویم. مطالبی که تا به اینجا در مورد صداها ذکر کردیم همگی مرتبط به خصوصیات صداها به صورت جداگانه یا لغتی خاص هستند. اما در مکالمات روزمره، ما کلمات را با سرعت نسبتاً بالایی پشت سر هم و تقریباً بدون مکث بکار میبریم و این امر باعث میشود که اصوات از یکدیگر تاثیر بپذیرند. پس تلفظ لغات در جمله تا حدی با تلفظ آنها بصورت جداگانه فرق دارد. برای درک بهتر این موضوع به جملهی زیر دقت کنید.
.Tim went to school
اگر از ما بخواهند که آوانوشتهی این لغات را بصورت جداگانه بنویسم میتوانیم به شکل زیر عمل کنیم:
/tɪm/ / wɛnt/ / tuː/ /skuːl/
اما اگر قرار باشد آوانوشتهی این کلمات را در قالب جمله ( یعنی آنگونه که یک شخص انگلیسی زبان این جمله را بیان میکند) بنویسیم، باید به شکل زیر عمل کنیم.
/tɪm wɛn tə skuːl/
همانطور که ملاحظه میکنید در اینجا صدای [t] در لغت went با دیگر صدای [t] در لغت to ادغام شده. همچنین صدای [uː] در لغت to به صدای /ə/ تبدیل شده است این همان تاثیرپذیری اصوات از یکدیگر است که در زبان انگلیسی coarticulation effect نامیده میشود. در اینجا با مهمترین نمونههای این پدیده آشنا میشویم.
Assimilation
Assimilation هنگامی اتفاق میافتد که یک صدا برخی از ویژگیهای صدای مجاور را جذب کرده تا به آن صدا شبیهتر شود. دلیل این امر راحتی در بیان یا ease of articulation است. به عنوان مثال عبارت could you در گفتار به شکل/ /kʊdʒ jə بیان میشود. همانطور که مطلاحظه میکنید، در اینجا صدای [d] به صدای [dʒ] تبدیل شده است. یعنی یک صدای alveolar به یک صدای palatal تبدیل شده یا همچنین میتوانیم بگوییم که یک stop به یک affricate تبدیل شده است. توجه داشته باشید که assimilation دو نوع دارد که عبارتند از partial assimilation و total assimilation .
در partial assimilation تغییر در یک صدا نسبی و در total assimilation این تغییر کلی است. یعنی صدای مورد نظر به یک صدای کاملاً متفاوت تبدیل میشود. به عنوان مثال عبارت this shoe را اگر بصورت لغت به لغت تلفظ کنیم میشود /ðɪs , ʃuː/. اما هنگام صحبت کردن، برای راحتی بیان، آن را به شکل /ðɪʃuː/ تلفظ میکنیم. همانطور که ملاحظه میکنید، در اینجا صدای [s] که یک صدای alveolar است به صدای دیگر یعنی [ ʃ ] که یک صدای palatal است تبدیل شده. پس در اینجا میتوان گفت که total/full assimilation رخ داده است. حال عبارت sit back را در نظر بگیرید. آوا نوشتهی این عبارت را چنین مینویسیم /sɪt bæk/. در گفتار اما این عبارت به شکل /sɪpbæk/ بیان میشود. بنابراین صدای [t] که یک صدای stop است به یک صدای stop دیگر یعنی [p] تبدیل شده. پس در اینجا با پدیدهی partial assimilation روبرو هستیم.
حالتهای مختلف assimilation
همچنین به یاد داشته باشید که assimilation ممکن است سه حالت مختلف داشته باشد. که عبارتند از aggressive assimilation, regressive assimilation و reciprocal assimilation . در حالت اول یعنی regressive assimilation یک صدا به صدای بعدی خودش مشابه میشود. در عبارت /sɪt bæk/ که به /sɪpbæk/ تبدیل شده، صدای [t] به این دلیل به [p] تبدیل میشود که با صدای بعد خودش یعنی [b] همخوانی بیشتری داشته باشد. در اینجا regressive assimilation رخ داده است. در حالت دیگر یعنی aggressive assimilation بر روی یک صدا تغییراتی ایجاد میشود تا با صدای قبل از خودش همخوانی و تشابه بیشتری داشته باشد. به عنوان مثال صدای [s] موجود در لغت bags بصورت [z] تلفظ میشود که دلیل این امر همان راحتی در تلفظ است.
در reciprocal assimilation دو صدای مجاور برروی هم دیگر تاثیر گذاشته و یک صدای مشترک تولید میکنند. به عنوان مثال عبارت don’t you در حالت عادی به شکل /doʊnt jʊ;/بیان میشود حال آنکه در گفتار به /doʊn tʆu: / تبدیل میشود. همانطور ملاحظه میکنید صداهای [t] و [ j ] از هم تاثیر پذیرفته و صدای [tʆ] را تشکیل دادهاند.
Dissimilation
گاهی به منظور راحتی در تلفظ یک صدا دُچار تغییراتی میشود تا با صدای مجاورش اختلاف بیشتری داشته باشد و در نتیجه راحت تر بیان شود. عبارت he thinks that در حالت لغت به لغت به شکل /hiː θɪŋks ðæt/ بیان میشود. در مکالمات روزمره اما این عبارت به شکل /hiː θɪŋks dæt/ درمیآید. در واقع صدای [ð] به صدای [d] تبدیل شده تا تفاوت بیشتری با [s] داشته باشد و راحتتر بیان شود. این یک نمونه از dissimilation در زبان انگلیسی است.
Elision
هنگامیکه یک صدا بخاطر راحتی در بیان حذف میشود و صدای دیگری جایگزین آن نمیشود، پدیدهی elision اتفاق افتاده است. اگربه تلفظ واژهی friendship دقت کنیم، متوجه میشویم که در گفتار این واژه به شکل [frɛnʃɪp] تلفظ میشود و در واقع صدای [d] حدف شده. چنین پدیدهایی همچنین در عبارت she must go نیز قابل مشاهده است که در آن صدای [t] حذف میشود.
Liaison
گاهی اوقات صداها ویژگیهای خود را حفظ میکنند و دُچار تغییر نمیشوند اما به هم میچسپند. معمولاً هنگامیکه یک consonant در انتهای یک لغت باشد و لغت مجاور با یک vowel شروع شده باشد، ممکن است consonant موجود در انتهای لغت اول به vowel موجود در ابتدای لغت دوم بچسپد. چنین پدیدهایی را liaison مینامیم. جملهی I ate an apple for breakfast را در نظر بگیرید. صدای [n] موجود در an به ابتدای لغت apple میچسپد و در واقع an apple را a napple میشنوییم.
/ æn æpəl/ → / æ næpəl/
سخن پایانی
مطالب مربوط به phonology محدود به این مقاله نمیشود و آنچه که در مقالهی حاضر ارائه شد تنها مقدمهای بر phonology محسوب میشود که نیاز اولیهی دانشجویان زبانشناسی و اساس درک مطالب پیچیده تر در این زمینه است. در مقالات آینده به بررسی رایجترین پدیدههای مربوط به phonology و همچنین دیگر نکاتی که باید در مورد syllable بدانید، میپردازیم . امیدواریم مطلب فوق برای شما مفیده بوده باشد و به دانستههایتان افزوده باشد.
عالی بود
ممنون از اینکه نظرتون رو با ما به اشتراک گذاشتید.
ممنون از اطلاعات کامل و جذاب راجب این مبحث مهم ک تو کتابای تخصصی تا توانستن پیچوندن😑
سلام. ممنون بابت اینکه دیدگاهتون رو با ما به اشتراک گذاشتید. خوشحالیم که این مطلب براتون مفید بوده.
عالی
عالی عالی هرچه بگم عالی کم گفتم بخدا خیلی خوب و مفید توضیح دادین هرچقدر تو کتب تخصصی سخت و پیچیدش کردن اینجا آسون و سادش کردین واقعا مرسی …موفق باشید🌷